C O N T E N T
—
D I G I T A L E I N T E G R A T I O N
Natural Language ProcessingNatural Language Processing Die Verarbeitung natürlicher Sprache mittels Computer-Algorithmen. Alltagssprache wird in eine Sprache übersetzt, die ein Computer verstehen und auf die er reagieren kann.
oder: Wie Computer lernen, die menschliche Sprache zu verstehen
L E S E D A U E R 3 0 M I N
↓ ↓ ↓

C O N T E N T
—
D I G I T A L E I N T E G R A T I O N
Natural Language Processing
oder: Wie Computer lernen, die menschliche Sprache zu verstehen
L E S E D A U E R 3 0 M I N
↓ ↓ ↓
Wenn wir Computer steuern, dann meistens über Maus, Tastatur oder einen TouchscreenTouchscreen Ein Bildschirm, der auf Berührungen reagiert. Touchscreens erlauben die Bedienung eines Computers nur mit dem Finger.. Seit einiger Zeit wird eine neue Form der Interaktion immer präsenter: die Sprachsteuerung ermöglicht es, mit einem Computer nur über die menschliche Stimme zu interagieren. Forschende aus dem RoboticLab der Technischen Hochschule Wildau arbeiten daran, Sprachsteuerung zu verbessern.

„Ich suche Bücher über technische Zeichnungen“, spricht Mara hinein in den Raum der Bibliothek der Technischen Hochschule Wildau. Doch anstelle eine:r freundlichen Mitarbeiter:in antwortet ihr ein etwa 1,20 Meter großer Roboter mit Namen Pepper. „Sie finden dazu Bücher in der Abteilung Tabellenwerke, 2. OG, gegenüber dem Lift.“ Was klingt wie ein Szenario aus der Zukunft, ist in den Laboren von Forschenden an der TH Wildau fast schon Realität.
Schon heute kann man in der Bibliothek auf dem Campus in Wildau auf den Roboter Pepper treffen. Die hilfreiche Maschine dient als Informationssystem für Besucher:innen, jedoch kann Mara derzeit noch nicht über die gesprochene Sprache, sondern nur über einen Touchscreen mit ihr interagieren. Damit sich das ändert, entwickeln Forscher:innen an der TH Wildau ein System zur Erkennung natürlicher Sprache.
Forschung an innovativen Technologien zu natürlicher Sprache
An der TH Wildau forscht Janett Mohnke mit ihren Mitarbeiter:innen im RoboticLab an innovativen Technologien im Bereich RobotikRobotik Forschungsfeld der Ingenieurs- und Computerwissenschaften mit Fokus auf Robotern. Roboter sind (teil-)autonome Maschinen, die bestimmte Aufgaben erfüllen, z.B. Produktion von Gütern oder Interaktion mit Menschen. und Mensch-Maschine-Interaktion. Dabei legen die Forscher:innen einen besonderen Fokus auf die Interaktion mit Maschinen mittels natürlicher Sprache. Natürliche Sprache ist, wie der Name andeutet, die für uns natürlichste Form der Interaktion mit unserer Umgebung. „Natürlich“ bedeutet in diesem Kontext aber auch, dass wir unser Vokabular nicht an die Maschine anpassen – und zum Beispiel sprechen wie ein technisches Handbuch – sondern dass wir so frei sprechen, wie wir es mit einem Menschen tun würden. Damit der Computer uns versteht, übernimmt ein AlgorithmusAlgorithmus Ein Algorithmus ist ein Stück Programm-Code und wird von einem Computer ausgeführt. Algorithmen können Berechnungen durchführen, Listen sortieren oder komplizierte Funktionen ausführen. die Aufgabe der Übersetzung in Maschinensprache. Der Fachbegriff dafür ist die Verarbeitung natürlicher Sprache, zu englisch „Natural Language Processing“ (NLPNatural Language Processing Die Verarbeitung natürlicher Sprache mittels Computer-Algorithmen. Alltagssprache wird in eine Sprache übersetzt, die ein Computer verstehen und auf die er reagieren kann.).
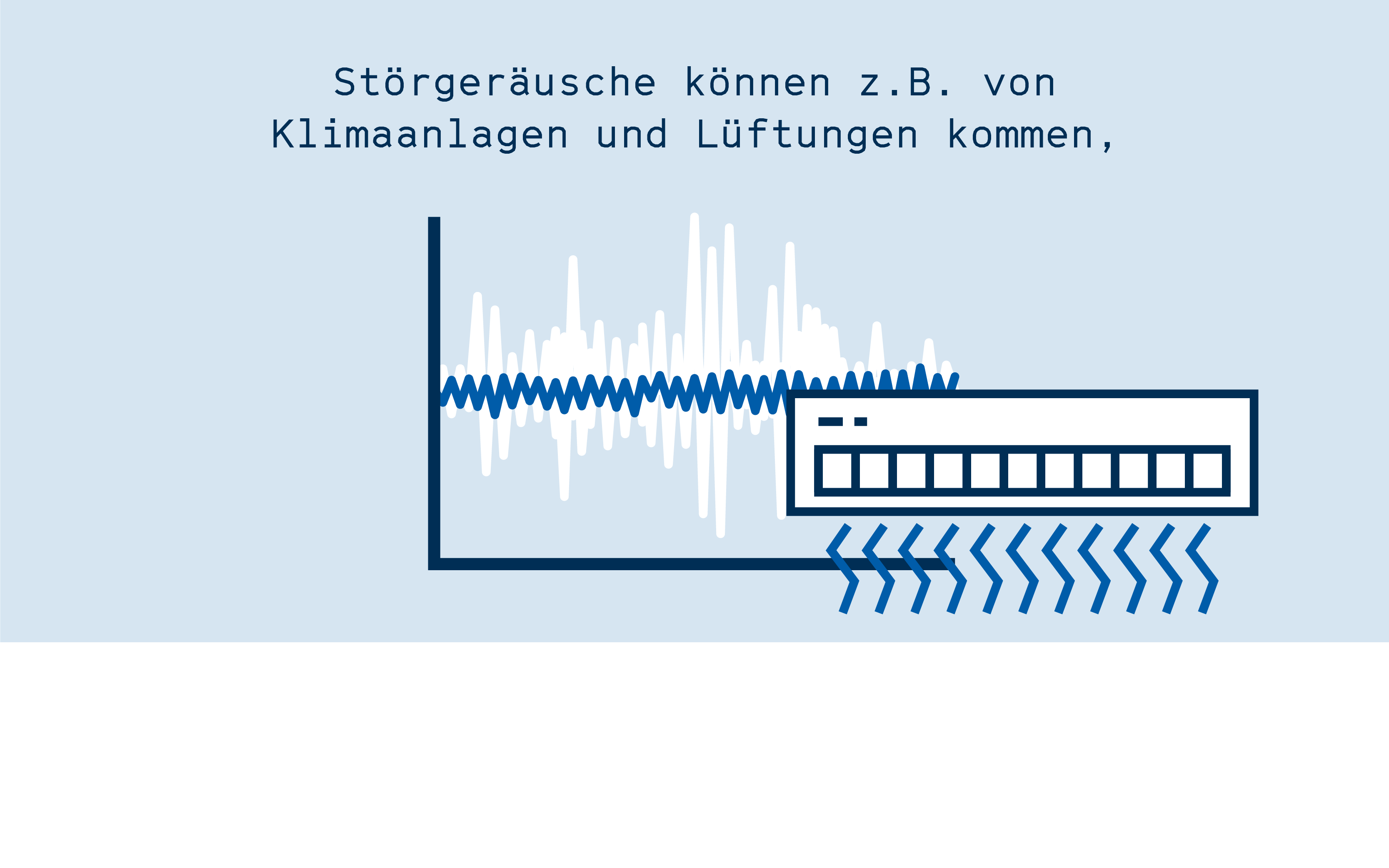
Im RoboticLabRoboticLab Das RoboticLab ist ein Fachgebiet an der Technischen Hochschule Wildau unter der Leitung von Prof. Dr. Janett Mohnke. bauen die Forschenden Roboter-Prototypen, mit deren Hilfe sie aktuelle Technologien sowohl für die Forschung und Produktentwicklung als auch für die Lehre entwickeln. Während viele kommerziell eingesetzte Systeme sich wie Black Boxes verhalten – man also von außen nicht beobachten und verstehen kann, wie das System arbeitet – setzt die TH Wildau auf die Entwicklung von eigenen Lösungen, basierend auf offener und freier Software, mit deren Hilfe ein tiefgehendes Verständnis der Technologie möglich ist. Dabei lösen die Forschenden aus der Arbeitsgruppe von Janett Mohnke auch das ein oder andere Problem, das kommerzielle Systeme plagt. So ist der eingangs erwähnte Bibliotheksroboter beispielsweise zwar theoretisch in der Lage, auch natürliche Sprache zu erkennen. Durch verschiedene Einschränkungen in der Hardware- und Softwarearchitektur scheitert die Spracherkennung des kommerziellen Systems allerdings immer wieder. Die mitgelieferte Spracherkennung funktioniert vor allem für Englisch und Japanisch, allerdings nur sehr unzureichend für die deutsche Sprache. Hinzu kommt, dass die verbauten Mikrofone von Störgeräuschen geplagt sind, sodass es für das System schwierig ist, Menschen fehlerfrei zu hören.
Die 6 Schritte der Spracherkennung
Damit Pepper Mara eine Frage beantworten kann, muss ein Computer die Sprache erst einmal verstehen. Der gesamte Prozess der Spracherkennung findet in einer Reihe von Schritten statt. Im ersten Schritt wird die Sprache aufgezeichnet. Anschließend werden Störgeräusche entfernt und dem Tonsignal danach einzelne Worte zugeordnet. An diesem Punkt steht zwar schon ein Satz aus Wörtern, aber der Computer versteht noch nicht deren Zusammenhang. Mithilfe von erlernten Datensets erkennt ein Algorithmus dann Verknüpfungen zwischen den Worten. Im vorletzten Schritt wird die erkannte Frage dann beantwortet und die Antwort schließlich mittels SprachsyntheseSprachsynthese Wenn ein Computer aus Text hörbare Sprache macht, heißt das Sprachsynthese. Computerprogramme analysieren die Silben in einem Text und erzeugen passende Töne, die für uns wie Sprache klingen. wieder ausgegeben. Das ganze läuft so schnell ab, dass sich daraus für die Nutzer:innen ein flüssiges Gespräch ergibt.


So versteht ein Computer natürliche Sprache
Schauen wir uns die Prozessschritte einmal genauer an. Für alle sprachbasierten Systeme ist der erste Schritt immer das Aufzeichnen der Tonsignale mit Hilfe eines Mikrofons. Wobei man hier eher von Mikrofonen im Plural sprechen sollte: tatsächlich übernimmt eine ganze Gruppe von Mikrofonen die Aufgabe der Tonaufzeichnung. Sogenannte Mikrofon-Arrays funktionieren ähnlich wie das menschliche Hören und sind damit auch in der Lage, die Richtung eines Tonsignals zu bestimmen. Der Schall erreicht die Mikrofone zu unterschiedlichen Zeitpunkten. Aus dieser Zeitdifferenz lässt sich dann die Richtung bestimmen, aus der der Ton kommt. Wenn das System die Richtung und den Ursprung des Tons kennt, kann es darauf reagieren und zum Beispiel Peppers Roboterkopf in Maras Richtung drehen.
Mikrofon-Arrays helfen auch dabei, das sogenannte Cocktailparty-Problem zu lösen. Wir Menschen können uns ohne weiteres auf unser Gegenüber konzentrieren, selbst wenn wir inmitten einer lauten Party stehen. Für ein System mit nur einem Mikrofon ist die Aufgabe jedoch nahezu unmöglich, weil Sprache aus allen Richtungen gleichzeitig auf das System trifft. Ein Mikrofon-Array schafft da Abhilfe, denn damit ist es möglich, Geräusche aus einer bestimmten Richtung zu hervorzuheben, während alle anderen ausgeblendet werden. Dieser Prozess wird auch BeamformingBeamforming Beim Beamforming berechnet ein Computer die Richtung, aus der ein Ton kommt. Dabei helfen mehrere im Kreis angeordnete Mikrofone. Durch Beamforming, kann ein Computer gezielt in eine Richtung "hören". genannt und trägt maßgeblich dazu bei, Hintergrundgeräusche zu entfernen.

So funktioniert ein Mikrofon Array
Ein Mikrofon-Array besteht aus vielen Mikrofonen und einem Chip zur Signalverarbeitung. Schall breitet sich wie eine Welle im Wasser aus. Der Schall erreicht die unterschiedlichen Mikrofone zu unterschiedlichen Zeitpunkten. Der eingebaute Chip berechnet aus den unterschiedlichen Zeitpunkten die Richtung, aus der der Schall ursprünglich gekommen ist. In einem zweiten Schritt kann der Chip dann gezielt nur in eine Richtung „hören“, also alles ausblenden, was nicht aus dieser Richtung kommt. Das ähnelt dem menschlichen Hören: auch unser Gehirn ist in der Lage, fokussiert nur Geräusche aus einer Richtung wahrzunehmen.
Hintergrundgeräusche sind generell ein großes Problem bei der Spracherkennung. Lüfter und Motorengeräusche am Roboter werden ebenso aufgezeichnet wie Gespräche im Umfeld oder die laute Kaffeemaschine ein paar Meter weiter. Das führt dazu, dass viele existierende Systeme schon daran scheitern, ein klares Signal aufzuzeichnen, das maschinell verarbeitet werden kann. Das Resultat sind fehlerhafte Versuche der Spracherkennung und Frustration bei den Nutzer:innen.





An der TH Wildau arbeitet Tobias Kannenberg daran, genau dieses Problem zu lösen. Er hat ein Verfahren entwickelt, das gezielt Störgeräusche entfernt und nur noch das möglichst ungestörte Sprachsignal übriglässt. Kannenberg verglich mehrere technische Ansätze miteinander, um so die bestmögliche Lösung zu finden:
Im ersten Ansatz analysiert seine Software das Hintergrundrauschen, z.B. von Lüftern, und zieht dann diese Frequenzen von der Tonaufzeichnung ab. Diese Methode nennt sich spektrale Subtraktionspektrale Subtraktion Verfahren zur Verarbeitung von Tonsignalen. Ein Störsignal (z.B. Rauschen) wird mathematisch von einem Tonsignal abgezogen, sodass ein rauschfreies Signal übrig bleibt.. Während das Signal durch die Methode anschließend zwar etwas weniger angenehm für menschliche Ohren klingt, so verbessert es doch die Qualität der Spracherkennung.
Im zweiten Ansatz von Kannenberg, dem „Spektralen Gatingspektrales Gating Verfahren zur Verarbeitung von Tonsignalen. Anhand eines Störgeräuschs (z.B. Rauschen) wird ein Schwellenwert für verschiedene Frequenzbereiche festgelegt. Nur Signale oberhalb dieses Schwellenwerts werden behalten, der Rest wird verworfen. Das kann die Verständlichkeit von Audioaufnahmen verbessern.“, wird die Aufnahme in viele Frequenzbereiche aufgeteilt, wobei für jeden Bereich ein Grenzwert festgelegt wird. Der Grenzwert entscheidet darüber, ob hier das Signal erhalten bleibt oder ob der Bereich auf Null heruntergeregelt wird. Dadurch bleiben nur die Frequenzbereiche erhalten, die während der Aufnahme die Stimme aufzeichnen, alle anderen Bereiche sind still und stören dadurch die Spracherkennung nicht.
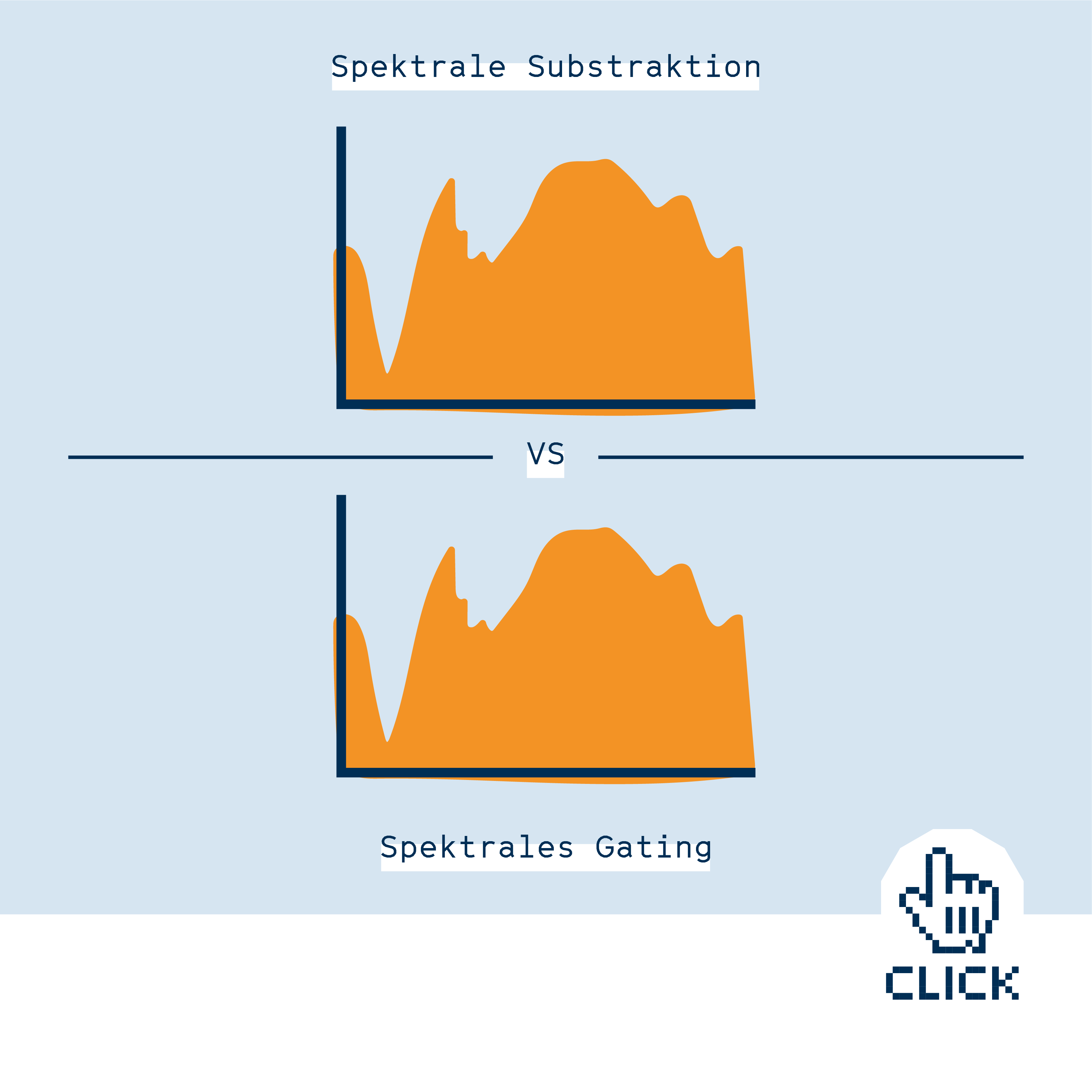
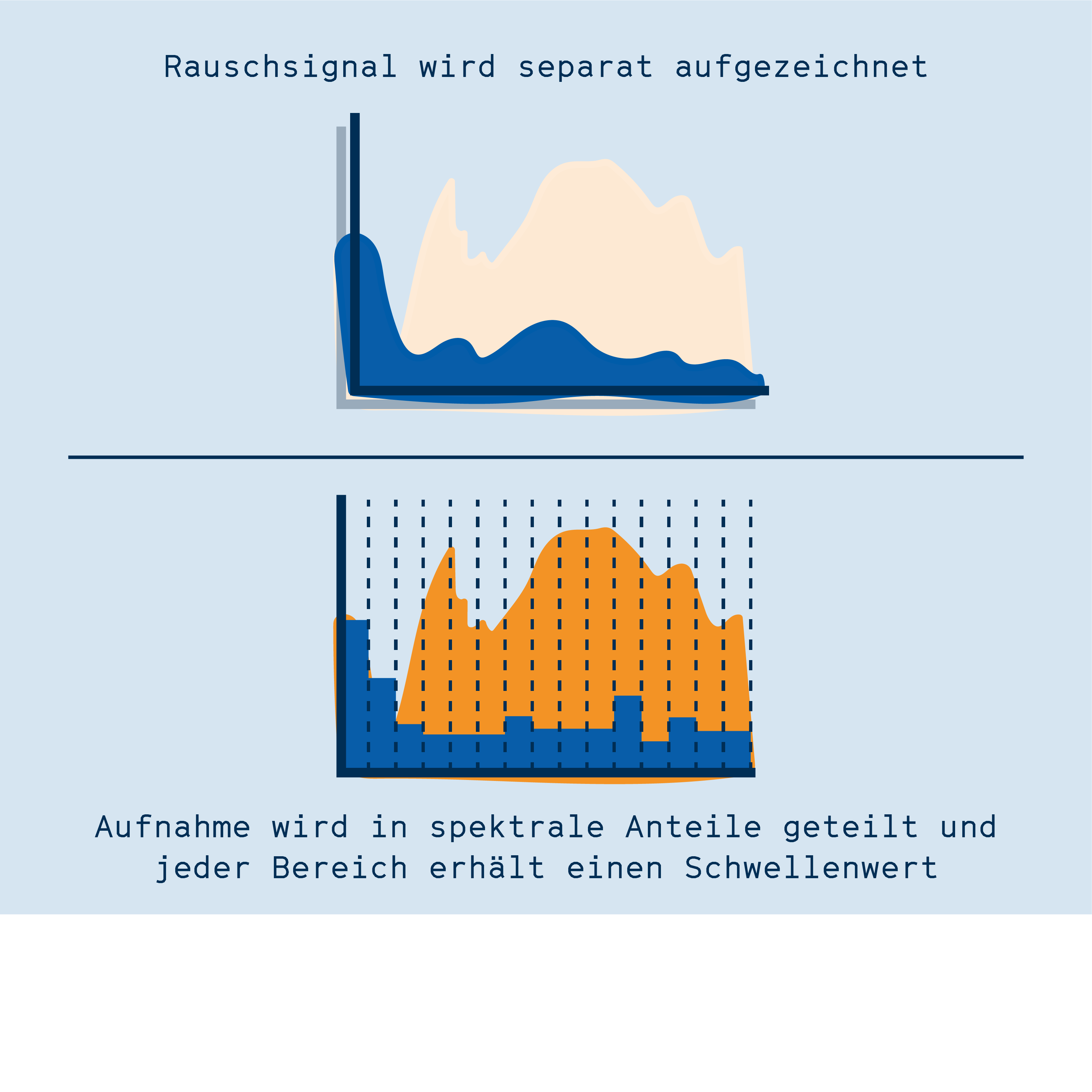
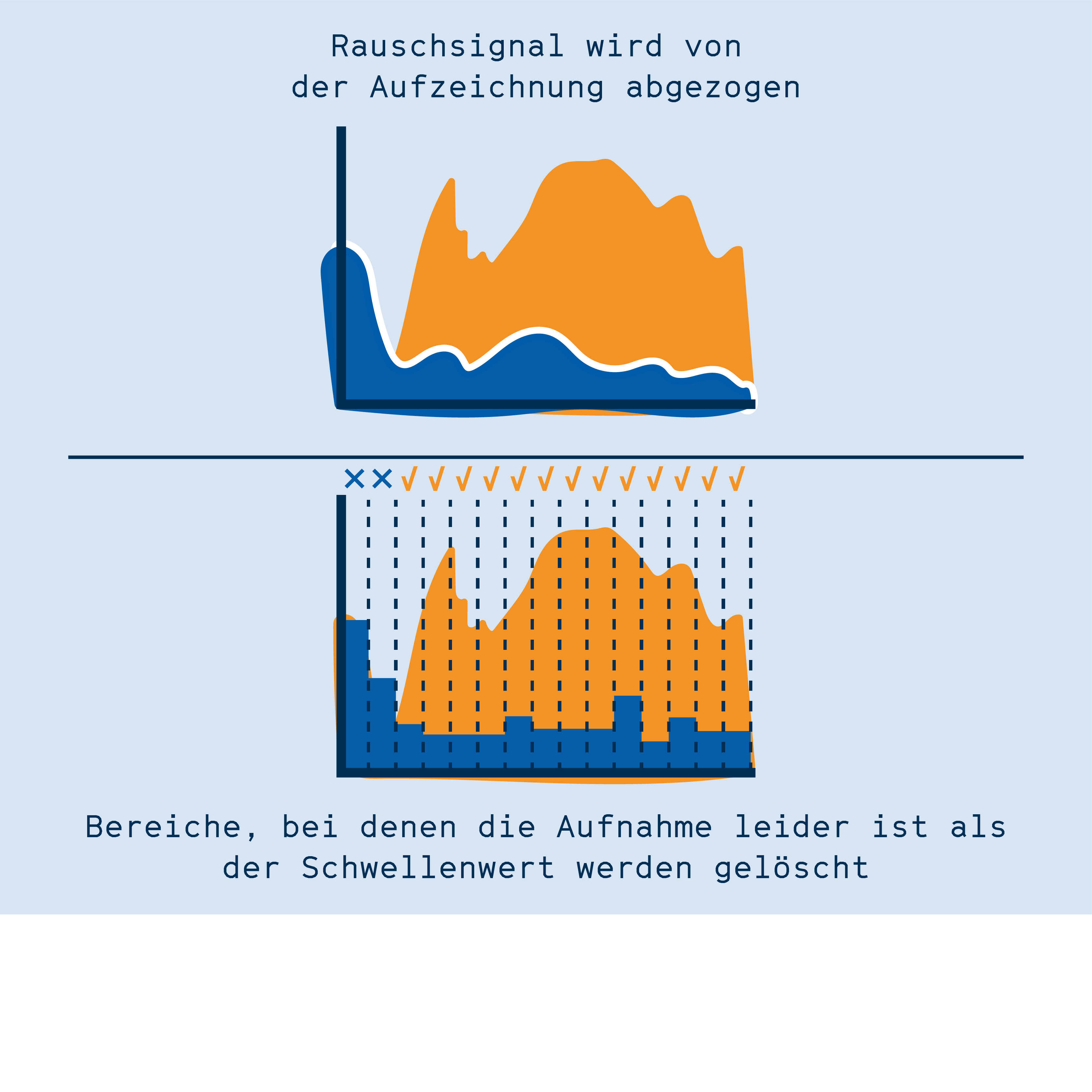
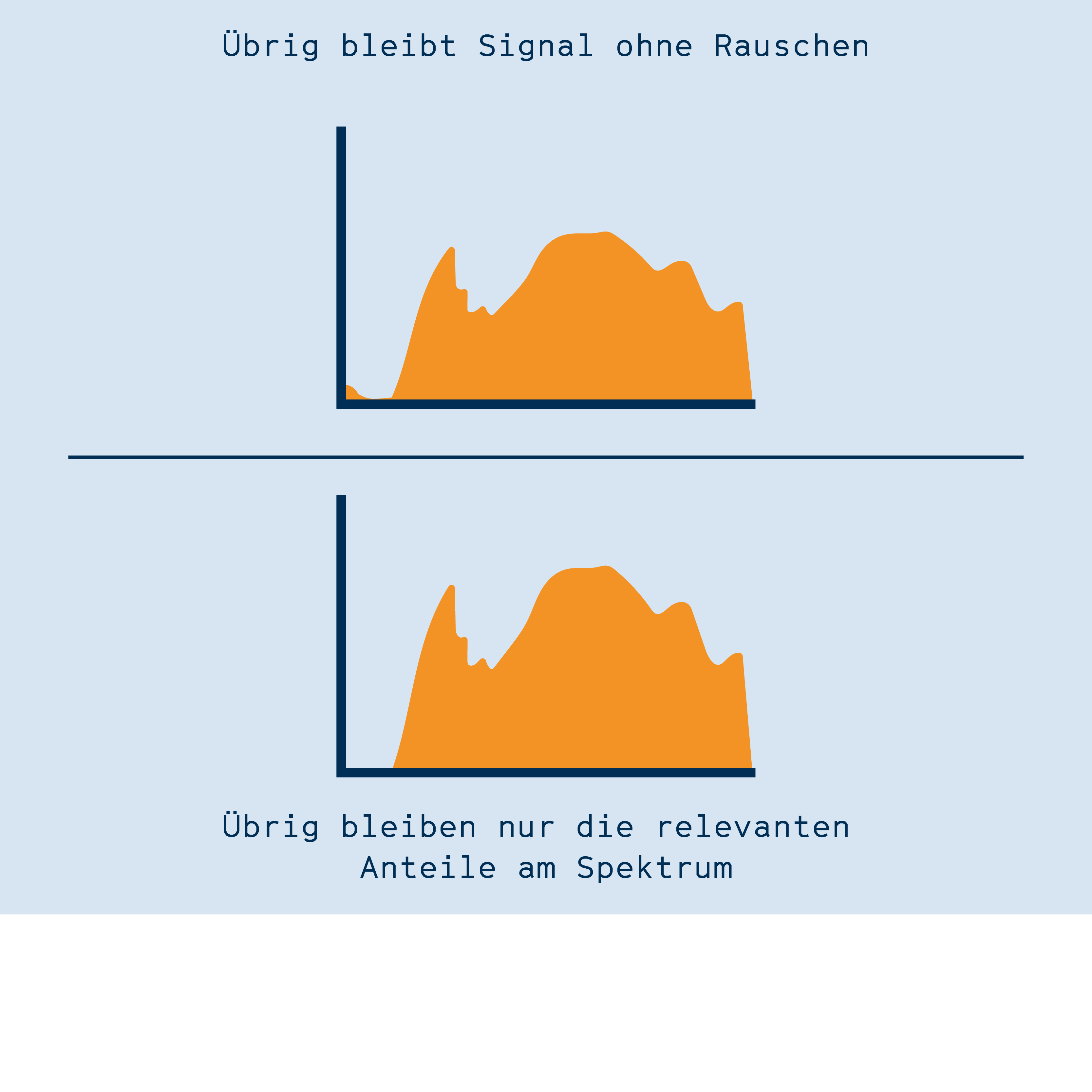
Unterschiedliche Ansätze zur Entfernung von Störgeräuschen
Um die verschiedenen Verfahren zur Entfernung von Störgeräuschen zu testen, nutzt Kannenberg einen standardisierten Testaufbau. Ein Lautsprecher spielt die immer gleiche Wortsequenz ab, Mikrofone auf dem Testroboter nehmen das Signal auf, und die Software entfernt Störgeräusche mit unterschiedlichen Methoden. Im Anschluss findet die eigentliche Spracherkennung statt. Ein Algorithmus ordnet den Tonsignalen Wörter zu und wandelt so die gesprochene Sprache in maschinenlesbaren Text um.
An dieser Stelle konnte Kannenberg die AlgorithmenAlgorithmus Ein Algorithmus ist ein Stück Programm-Code und wird von einem Computer ausgeführt. Algorithmen können Berechnungen durchführen, Listen sortieren oder komplizierte Funktionen ausführen. zur Entfernung von Störgeräuschen miteinander vergleichen. Dabei wurde klar, dass je nach verwendeter Spracherkennungsmethode ein anderes Verfahren zur Vorverarbeitung das optimale Ergebnis lieferte. Dabei ist das Potenzial aber noch nicht ausgeschöpft – besonders schlaue Algorithmen, die das Rauschen noch besser analysieren und dann vom Signal abziehen, könnten weitere Verbesserungen bringen. Die von Kannenberg gewählten Methoden bilden jedoch eine wichtige Grundlage, um ein robustes System der Spracherkennung zu entwickeln.
Sprache verstehen dank maschinellem Lernen
Im Prozess der Spracherkennung sind zu diesem Zeitpunkt Maras Worte zwar als solche erkannt, allerdings hat der Roboter, bzw. der Computer zur Spracherkennung, noch kein Verständnis über Sinn und Inhalt des Gesagten. Um die gesprochenen Worte tatsächlich zu verstehen und deren Sinn zu erfassen, kommen weitere Algorithmen zum Einsatz. Philipp Müller, der ebenfalls im RoboticLab der TH Wildau arbeitet, entwickelt die Software, die Texte versteht.
Im letzten Jahrzehnt haben mehrere Softwarelösungen zu enormen Fortschritten bei der Spracherkennung geführt. Mithilfe von beispielsweise word2vecword2vec Ein Verfahren, mit dem Computer menschliche Sprache analysieren können. Jedes Wort wird ein Zahlenwert zugeordnet. Worte mit ähnlichen Bedeutungen, haben ähnliche Zahlenwerte. Damit kann ein Computer dann Zusammenhänge berechnen. (sprich „Word To Vec“) können Entwickler:innen jedem Wort einen Platz in einem mehrdimensionalen virtuellen Raum zuordnen[1]word2vec selber ausprobieren (engl.). Das bedeutet, dass Worte, die inhaltlich zusammenhängen, auch in diesem Raum eng beieinander stehen. Das ermöglicht zwar einerseits viele neue Methoden zur Texterkennung, scheitert aber auch immer wieder an den Eigenheiten unserer Sprache. Für Algorithmen wie word2vec ist es zum Beispiel äußerst schwierig, mehrdeutige Begriffe – HomonymeHomonym Gleichklingende Worte mit unterschiedlicher Bedeutung (Bank: Geldinstitut oder Sitzgelegenheit) – auseinanderzuhalten. Sollte „Bank“ sich in der Nähe von „Sitzen“ befinden, oder in der Nähe von „Geld“?
Abhilfe schaffen da Algorithmen, die auch Kontext verstehen können. Sogenannte Transformer-ModelleTransformer-Modelle Verfahren zur Verarbeitung menschlicher Sprache durch Computer. Jedes Wort erhält einen Zahlenwert, der abhängig vom Kontext des Wortes ist. So können auch gleichklingende Worte mit mehreren Bedeutungen korrekt zugeordnet werden. betrachten Worte nicht einzeln, sondern setzen sie in den Kontext der umliegenden Worte[2]Transformer Modelle erklärt (YouTube, engl.). Dadurch verstehen diese Algorithmen den Sinn von Worten besser und können dazu eingesetzt werden, um Fragen präzise zu beantworten. Dies geht sogar so weit, dass solche fortgeschrittenen Spracherkennungsalgorithmen in der Lage sind, Absichten und relevante Objekte in der Satzstruktur zu erkennen. So wird im Satz „Ich möchte meine Jacke wegschließen“ erkannt, dass das relevante Objekt „Jacke“ und die Absicht „wegschließen“ ist. Die passende Antwort könnte dann auf den Ort der Schließfächer und deren Benutzung verweisen.
Solche Systeme sind schon heute im Einsatz, vollkommen unabhängig von Robotern. ChatbotsChatbot Ein Programm, mit dem man sich unterhalten kann – in Wort oder Schrift. Der Chatbot analysiert das Gesagte und gibt eine passende Antwort in natürlicher Sprache. sind Systeme, die auf schriftliche Fragen Antworten geben können. Solche Chatbots werden gerne auf Webseiten verwendet, um grundlegende Fragen von Nutzer:innen zu beantworten. Sie setzen auf ähnliche Lösungen wie die Entwicklungen an der TH Wildau, wenn auch mit geringerer Komplexität. Wer selbst einmal einem ChatbotChatbot Ein Programm, mit dem man sich unterhalten kann – in Wort oder Schrift. Der Chatbot analysiert das Gesagte und gibt eine passende Antwort in natürlicher Sprache. bei der Arbeit zusehen möchte, kann dies im Testbed der TH Wildau tun. Dort verrichtet ein von Müller entwickeltes System seinen Dienst und erklärt gleichzeitig dabei, was im Hintergrund des Chatbots abläuft.
Für eine effiziente und korrekte Antwort bedarf es aber nicht nur den geschickten Einsatz von Algorithmen, sondern vor allem Training. Die verwendeten Transformer-Modelle für die Spracherkennung setzen daher auf maschinelles Lernenmaschinelles Lernen Ein Fachbereich der Computerwissenschaften bei dem statistische Methoden dazu genutzt werden, Programme für bestimmte Aufgaben zu trainieren. Ein Programm "lernt" in einer sehr großen Menge an Trainingsdaten Muster zu erkennen. Mit diesen erkannten Mustern kann das Programm im Anschluss Vorhersagen zu konkreten Fragen liefern.. Dazu gehört das Training mit ausgewählten Daten. Die TrainingsdatenTrainingsdaten Trainingsdaten werden beim maschinellen Lernen dazu eingesetzt, Programme darauf zu trainieren, Muster zu erkennen. Trainingsdaten müssen für die angestrebte Aufgabe passen. Die Zusammensetzung der Trainingsdaten entscheidet über das Ergebnis des maschinellen Lernens – schlechte Trainingsdaten führen zu einem schlechten Ergebnis. beinhalten dabei sowohl Frage als auch die passende Antwort. Schließlich, nach vielen Tausend Datensätzen, findet der Algorithmus Zusammenhänge zwischen bekannten Fragen und Antworten, mit denen er auch bei neuen Fragen die richtige Antwort auswählen kann.
Training macht den Computer fit für die Spracherkennung
Die Auswahl der korrekten Trainingsdaten ist keine triviale Aufgabe. Absichtliche und unabsichtliche Verzerrungen in den Trainingsdaten werden ohne weiteres vom Algorithmus reproduziert. So hat beispielsweise ein Bilderkennungsalgorithmus für Fische einen Fisch daran erkannt, dass Finger des Anglers mit im Bild waren[3]KI erkennt Fische an den Händen derer, die sie halten (engl.). Diese Finger fehlten auf Bildern von anderen Tieren, was dazu führte, dass der Algorithmus die falschen Schlüsse zog: Am Ende hat der Algorithmus nicht Fische, sondern das Vorhandensein von Fingern auf den Bildern erkannt[4]Neuronale Netze folgen einer einfachen Strategie zur Bilderkennung (engl.).
Doch nicht immer führen die Fehler beim maschinellen Lernen zu einer amüsanten Anekdote. Im März 2016 veröffentlichte Microsoft eine Künstliche IntelligenzKünstliche Intelligenz Programm, das mithilfe von maschinellem Lernen darauf trainiert wurde, eine bestimmte Aufgabe zu meistern. KI können menschliche Sprache imitieren, Muster erkennen, Bilder analysieren oder Spiele spielen. (KIKünstliche Intelligenz Programm, das mithilfe von maschinellem Lernen darauf trainiert wurde, eine bestimmte Aufgabe zu meistern. KI können menschliche Sprache imitieren, Muster erkennen, Bilder analysieren oder Spiele spielen.), die auf Twitter mit Menschen kommunizierte. Das Problem: Das System war darauf eingestellt, kontinuierlich dazuzulernen. Jede Antwort von Twitternutzer:innen schärfte weiter das Profil der KI, mit fatalen Folgen. Trolle kaperten das Projekt mit menschenverachtenden Aussagen, die anschließend von der KI reproduziert wurden. Nur 16 Stunden nach Beginn des Experiments zog Microsoft den Stecker und beendete das Projekt[5]Der Bot Tay wird von Trollen gekapert und in Folge abgeschaltet (engl.)[6]Mehr über Tay in der deutschen Wikipedia.
Bei der Auswahl der Trainingsdaten ist daher große Vorsicht geboten[7]Wer sind wir? Warum künstliche Intelligenz immer ideologisch ist (republik.ch). Denn gerade kleine Feinheiten, die nicht sofort ins Auge springen, können die größten Probleme erzeugen. So kann beispielsweise eine KI, die basierend auf bisherigen Einstellungspraktiken im Unternehmen neue Bewerber:innen beurteilt, dazu führen, dass ohnehin unterrepräsentierte Gruppen auch weiterhin nicht eingestellt werden. Die KI tut das dann nicht aus böswilliger Absicht, sondern im Einklang mit den Trainingsdaten, die ihr zur Verfügung standen.
Wie kann man die Trainingsdaten bestmöglich auswählen? Hier machte sich eine Kooperation zwischen der TH Wildau und einem Industriepartner bezahlt. Die Forschenden entwickelten dabei gemeinsam mit Mitarbeiter:innen der Sense.Ai.Tion GmbH einen großen Trainingsdatensatz in deutscher Sprache, um damit ein Spracherkennungsmodell zu trainieren. Das besondere an diesem Projekt: Die meisten kommerziell verfügbaren Modelle basieren auf der englischen Sprache. Die gemeinsame Arbeit von TH Wildau und der Sense.AI.tion GmbH leistet daher einen bedeutenden Beitrag, Spracherkennung auch auf Deutsch zu ermöglichen. Die Ergebnisse aus dieser Kooperation fließen ebenfalls in die Entwicklung des Pepper Roboters in der Bibliothek der Hochschule.
Eine Antwort der Maschine
Zurück zu unserer Fragestellerin Mara. Dank der an der TH Wildau entwickelten Algorithmen hat der Computer nun nicht nur die Frage verstanden, sondern auch eine passende Antwort gefunden. Diese liegt zuerst nur im Computer vor, Mara sieht davon noch nichts. Erst wenn der Algorithmus die Teile der Antwort zu einem Satz zusammenfügt und diese per Sprachsynthese über einen Lautsprecher ausgibt, kann Mara die Antwort auch hören. Doch hier ist die Aufgabe von Pepper noch nicht zu Ende. Denn Pepper kann auch auf eventuelle Rückfragen im Kontext voriger Fragen reagieren, und zum Beispiel nähere Informationen zur gesuchten Kategorie an Fachbüchern geben.
Der Prozess aus Spracherkennung, Sprachverständnis und Sprachausgabe findet innerhalb von wenigen Sekunden statt. Die komplexen Schritte der Signalverarbeitung gefolgt von der Anwendung von Algorithmen zum Textverständnis laufen vollständig im Hintergrund ab. Dabei ist jeder Schritt vom Ergebnis der vorhergegangenen Schritte abhängig: Nur wenn der Ton gut aufgezeichnet werden kann, können auch die Störgeräusche entfernt werden. Und nur, wenn die Aufnahme klar verständlich ist, kann ein Algorithmus auch den Sinn der Aufnahme entschlüsseln.
Die Forschenden der TH Wildau entwickeln und verbessern alle Teile des Verarbeitungsprozesses natürlicher Sprache parallel. So erreichen sie nicht nur ein optimales Ergebnis, sondern erlangen auch einen viel tieferen Einblick in die Problemstellungen. Mit diesen Erkenntnissen können sie daraufhin gezielt Lösungen entwickeln.
In Zukunft wird sich Sprache zu einem weiteren Weg der Gerätesteuerung etablieren, so wie zuvor schon Tasten und Touchscreens. Dabei bringt die Sprachsteuerung eigene Vorteile mit sich, die ganz neue Nutzungsräume eröffnen, wie etwa der Einsatz in der Robotik. Aber auch Fahrzeuge, AssistenzsystemeAssistenzsystem Ein Assistenzsystem unterstützt Menschen bei bestimmten Aufgaben. Typisch sind zum Beispiel kleine Geräte, die mittels Sprachsteuerung kontrolliert werden, und die dabei helfen, Lichter ein- und auszuschalten. oder Geräte in der Pflege werden in Zukunft auf Sprachsteuerung setzen. Die Forschung und Entwicklung an Hochschulen wie der TH Wildau in Kooperation mit lokalen Unternehmen trägt dazu bei, hier innovative Lösungen zu entwickeln, die wir alle eines Tages nutzen werden.

Konzeption + Text:
Joram Schwartzmann
joram.schwartzmann@th-wildau.de
Grafische Umsetzung:
Peter Kessel
peter.kessel@th-wildau.de
Weitere Informationen
Mehr Informationen zum Thema finden Sie auch in unserem Podcast.
Das RoboticLab der TH Wildau vereint Forschung und Lehre rund um das Thema Robotik.
Im Innovation Hub 13 sorgen die Transferscouts für den Transfer von Wissen und Technologien in die Wirtschaft.
Im Testbed des Innovation Hub 13 können innovative Technologien zuhause ausprobiert werden.
Quellen